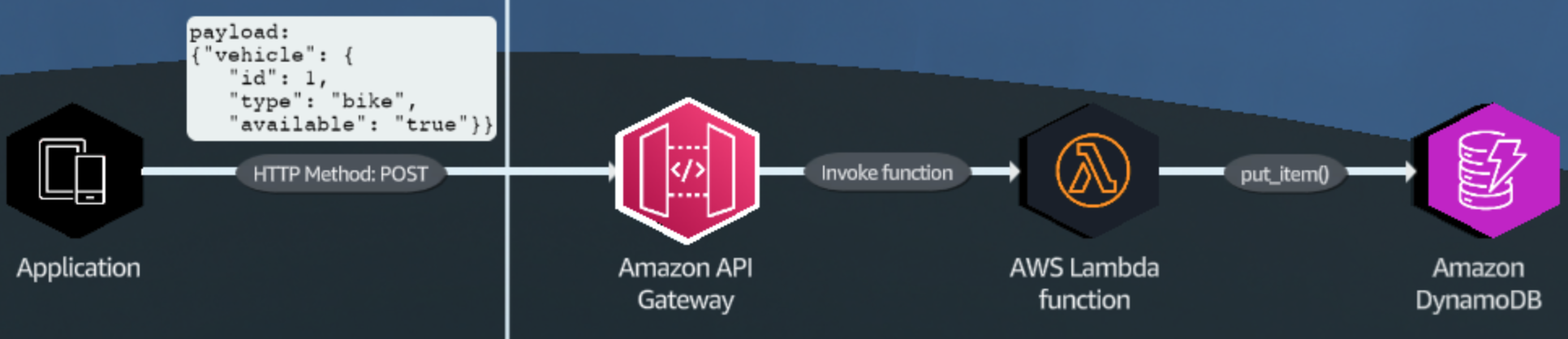
integrate with AWS Lambda
integrate with AWS Lambda
 * Turn on `ConsistentRead`if you want strongly consistent read. Because the `PutItem` or `UpdateItem` might not reflect to your replicas.
* Cache for popular items. Use DAX for caching reads.
## Concepts
* **Table, item, attribute:** are core components of DynamoDB.
* *Table*: collection of *item*.
* *Item*: collection of *attribute*.
* **Primary key**: unique identifier each item in table.
* GSI (***Global Secondary Index***) uses a different partition key as well as a different sort key to speed up queries on non-key attributes. All reads from GSIs and streams are eventually consistent.
* **Partition key**: mandatary. -> Hash function -> Hash key.
* **Sort key** (optional): additional for querying data.
* LSI (***Local Secondary Index***)
* The same partition key as the base table.
* Both tables and LSIs provide two read consistency options: *eventually consistent*(default) and *strongly consistent* reads.
* ***WCU***:
* 1 api write data to your table = 1 write request
* For 1 item upto 1KB in size
* 1 WCU = 1 standard write
* 1 WCU = 0.5 transactional write. Or 1 transational write require 2 WCUs.
* ***RCU***:
* 1 api call to your data is a read request (strongly consistent, eventually consistent, or transactional).
* For item upto 4KB
* 1 RCU = 1 strongly consistent read request / sec
* 1 RCU = 2 eventually consistent read request / sec
* 1 RCU = 0.5 transactional read request / sec
* 1 RCU = 4KB/sec. 1WCU = 1KB/sec -> in one second, you can read 4KB but write only 1KB.
* ***PartiQL***: SQL-compatible query language that makes it easier to interact with data in AWS services like Amazon DynamoDB, [S3 Select](https://mamawhocode.gitbook.io/aws/storage/s3#s3-select-and-glacier-select), and [Glacier Select](https://mamawhocode.gitbook.io/aws/storage/s3#s3-select-and-glacier-select).
* ***Composite key*** = Partition key + Sort key.
* ***Throttled***: occur when the configure RCU or WCU exceeded. `ProvisionedThroughputExceededException`. Reasons for this exception are:
* request rate > provision throughput
* wrong choice of partition key -> uneven distribution of data
* frequent access of the same key in a partition -> hot key, if your access pattern exceed 3000 RCU, and 1000 WCU, regardless of the capacity (provisioned or on-demand)
{% hint style="info" %}
The AWS SDKs for DynamoDB automatically retry requests that receive this exception. Unless your retry queue is too large to finish -> your request is eventually successful.
{% endhint %}
## Trivia
* DAX is an in-memory acceleration service that **accelerates DynamoDB tables**. DAX cannot be used with other databases.
* DynamoDB can support tables of virtually *any size*.
* DynamoDB can scale to > 10 trillion requests / day with > 20 milion request/sec.
* 1 single DynamoDB scan can retrieve max 1MB.
* The maximum size of *an item* in Dynamo table is 400 KB.
* the `LIMIT` parameter in query string is not the number of matching items. It is the maximum number of items to evaluate. :smile:
* Each table can have up to 20 GSI and 5 LSI (default quota).
* You can add Replica only when the table is empty. So do it before inserting any data.
* Turn on `ConsistentRead`if you want strongly consistent read. Because the `PutItem` or `UpdateItem` might not reflect to your replicas.
* Cache for popular items. Use DAX for caching reads.
## Concepts
* **Table, item, attribute:** are core components of DynamoDB.
* *Table*: collection of *item*.
* *Item*: collection of *attribute*.
* **Primary key**: unique identifier each item in table.
* GSI (***Global Secondary Index***) uses a different partition key as well as a different sort key to speed up queries on non-key attributes. All reads from GSIs and streams are eventually consistent.
* **Partition key**: mandatary. -> Hash function -> Hash key.
* **Sort key** (optional): additional for querying data.
* LSI (***Local Secondary Index***)
* The same partition key as the base table.
* Both tables and LSIs provide two read consistency options: *eventually consistent*(default) and *strongly consistent* reads.
* ***WCU***:
* 1 api write data to your table = 1 write request
* For 1 item upto 1KB in size
* 1 WCU = 1 standard write
* 1 WCU = 0.5 transactional write. Or 1 transational write require 2 WCUs.
* ***RCU***:
* 1 api call to your data is a read request (strongly consistent, eventually consistent, or transactional).
* For item upto 4KB
* 1 RCU = 1 strongly consistent read request / sec
* 1 RCU = 2 eventually consistent read request / sec
* 1 RCU = 0.5 transactional read request / sec
* 1 RCU = 4KB/sec. 1WCU = 1KB/sec -> in one second, you can read 4KB but write only 1KB.
* ***PartiQL***: SQL-compatible query language that makes it easier to interact with data in AWS services like Amazon DynamoDB, [S3 Select](https://mamawhocode.gitbook.io/aws/storage/s3#s3-select-and-glacier-select), and [Glacier Select](https://mamawhocode.gitbook.io/aws/storage/s3#s3-select-and-glacier-select).
* ***Composite key*** = Partition key + Sort key.
* ***Throttled***: occur when the configure RCU or WCU exceeded. `ProvisionedThroughputExceededException`. Reasons for this exception are:
* request rate > provision throughput
* wrong choice of partition key -> uneven distribution of data
* frequent access of the same key in a partition -> hot key, if your access pattern exceed 3000 RCU, and 1000 WCU, regardless of the capacity (provisioned or on-demand)
{% hint style="info" %}
The AWS SDKs for DynamoDB automatically retry requests that receive this exception. Unless your retry queue is too large to finish -> your request is eventually successful.
{% endhint %}
## Trivia
* DAX is an in-memory acceleration service that **accelerates DynamoDB tables**. DAX cannot be used with other databases.
* DynamoDB can support tables of virtually *any size*.
* DynamoDB can scale to > 10 trillion requests / day with > 20 milion request/sec.
* 1 single DynamoDB scan can retrieve max 1MB.
* The maximum size of *an item* in Dynamo table is 400 KB.
* the `LIMIT` parameter in query string is not the number of matching items. It is the maximum number of items to evaluate. :smile:
* Each table can have up to 20 GSI and 5 LSI (default quota).
* You can add Replica only when the table is empty. So do it before inserting any data.