Kinesis
a suite of services that helps you work with streaming data
AWS Document | Data Analytics | Kinesis Streams | Apache Flink
Overview
collect, process, analyze video & data streams in
real-time.Real-time data: Application logs, Metrics, Website clickstreams, IoT telemetry data.
operate in several modes
Data Streams
Firehose
Managed Apache Flink (old: Data Analytics)
Video stream

Use cases
Application monitoring
Fraud detection
Live game leaderboards
IoT
Sentiment analysis
Features
Service
Description
Use Case
Kinesis Data Streams
capture, process & store data stream
Ingesting data from various sources, processing data in real-time, performing real-time (millisecond) analytics
Kinesis Firehose
built-in Transform, deliver streaming data directly to AWS services
near real-time (buffer 1 min to 15min) storing and analyzing large amounts of data over time without managing your own data pipeline, simple transformation, auto scaling
Kinesis Data Analytics -> Amazon Managed service for Apache Flink (MSAF)
Process and analyze streaming data using standard SQL queries
Real-time data analytics on data streams without the need for specialized programming skills
Kinesis Video Streams
Securely stream video from connected devices to AWS for analysis and processing
Capturing video from security cameras, drones, and IoT sensors, and analyzing the data in real-time
Kinesis Data Streams

Producer
Kinesis Agent
AWS SDK
Kinesis Producer Library (KPL)
Consumer
Kinesis Data Analytics: use an Amazon Kinesis Data Analytics application to process and analyze using SQL or Java.
Kinesis Firehose: use an Amazon Kinesis Data Firehose delivery stream to process and store records in a destination.
Kinesis Client Library (KCL): use Kinesis Client Library to develop consumers.
Capacity modes
Provisioned mode
Choose the number of shards
Scale
manuallyusing API
On-demand mode
No nead to provision or manage capicty
Scale automatically based on observed throughput peak during the last 30 days.
Kinesis Firehose
Serverless, fully managed, automatic scaling.
Supports custom data transformations using Lambda

Producer
Consumer
AWS S3
Redshift
OpenSearch
3rd party: Splunk, MongoDB, DataDog, NewRelic, HoneyCom...
HTTP Endpoint
Use cases:
Main usage scenarios for CloudWatch metric streams: Data lake— Create a metric stream and direct it to an Amazon Kinesis Data Firehose delivery stream that delivers your CloudWatch metrics to a data lake such as Amazon S3.
Kinesis Data Analytics/ Managed service for Apache Flink (MSAF)
Reads and processes real-time streaming data.

Kinesis Data Analytics/ MSAF
Kinesis Video Streams
Best practices
Increase number of shards in your Kinesis Data stream to handle increase throughput/traffic (resolve
ProvisionedThroughputExceededproblem).Use random partition key to deal with hot shard problem (unevenly distributed stream)
Trivia
real-timeornear-real time= Kinesis Data Stream.Kinesis Data stream uses the partition key associated with each data record to determine which shard a data record belongs to.
Multiple Kinesis Data Streams applications can consume data from a stream.
Firehose does not support DynamoDB. refer
PutRecordsrequest can support up to 500 records. Each record in the request can be as large as 1 MiB, up to a limit of 5 MiB.ProvisionedThroughputExceededException: when there is throttling, it best practices toImplement retries with exponential backoff.
Increase Shard Count
Optimize Data Send Rate: If possible, batch records to use the
PutRecordsAPIReduce the frequency and/or size of the requests.
Uniformly Distribute Partition Keys
Redshift applies compression to columns to reduce storage size and improve query speed. To determine the best compression encoding for a table, use the
ANALYZE COMPRESSIONcommand.
Concepts
Producer (upstream): a producer
putrecords into KinesisConsumer (downstream): a consumer
getrecords from KinesisSharding: DB sharding is the processing of breaking up large tables into multiple smaller tables, or chunks called shards. So sharding is horizontal partitioning.
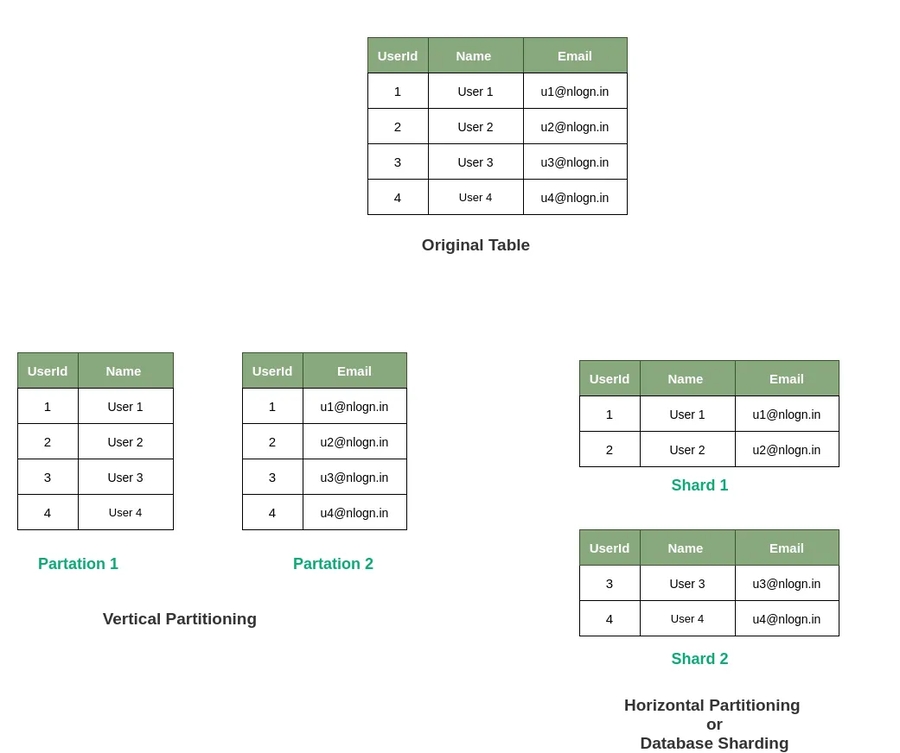
a shard is a unit of throughput capacity.
The number of instances does not exceed the number of open shards. Each shard is processed by exactly one KCL worker and has exactly one corresponding record processor, so you never need multiple instances to process one shard. However, one worker can process any number of shards, so it's fine if the number of shards exceeds the number of instances.
Clickstream: Clickstream data is a record of a user's activity on the internet, including every click they make while browsing a website or using an application.
Sub-Optimal Encoding: occurs when the applied compression method is not the best fit for the data, leading to inefficiencies in storage and performance.
Last updated